
A²-Edit:突破物体类别与掩码精度限制,实现精准参考图编辑
A²-Edit:突破物体类别与掩码精度限制,实现精准参考图编辑上海交通大学联合上海创智学院团队提出 A²-Edit,它以统一框架支持任意物体类别和任意精度掩码,通过混合 Transformer 专家路由、掩码退火训练及 50 万级多品类数据,让用户只需给出粗略区域,也能完成身份一致、结构完整、自然融合的参考图引导局部编辑。
来自主题: AI技术研报
6584 点击 2026-08-01 10:44
 搜索
搜索
上海交通大学联合上海创智学院团队提出 A²-Edit,它以统一框架支持任意物体类别和任意精度掩码,通过混合 Transformer 专家路由、掩码退火训练及 50 万级多品类数据,让用户只需给出粗略区域,也能完成身份一致、结构完整、自然融合的参考图引导局部编辑。
最近,谷歌连失两员大将。短短三天内,先是 Transformer 论文共同作者 Noam Shazeer 离开谷歌加入 OpenAI;紧接着诺贝尔奖得主、AlphaFold 负责人 John Jumper 转投 Anthropic 麾下。

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。
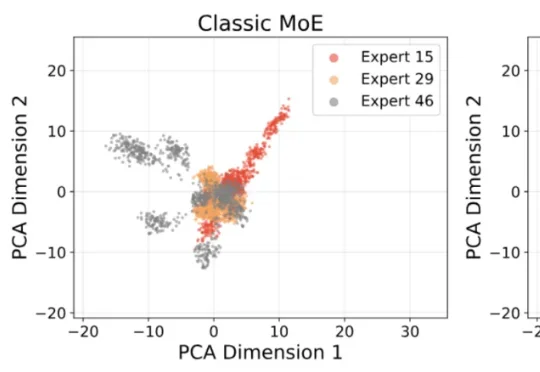
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。
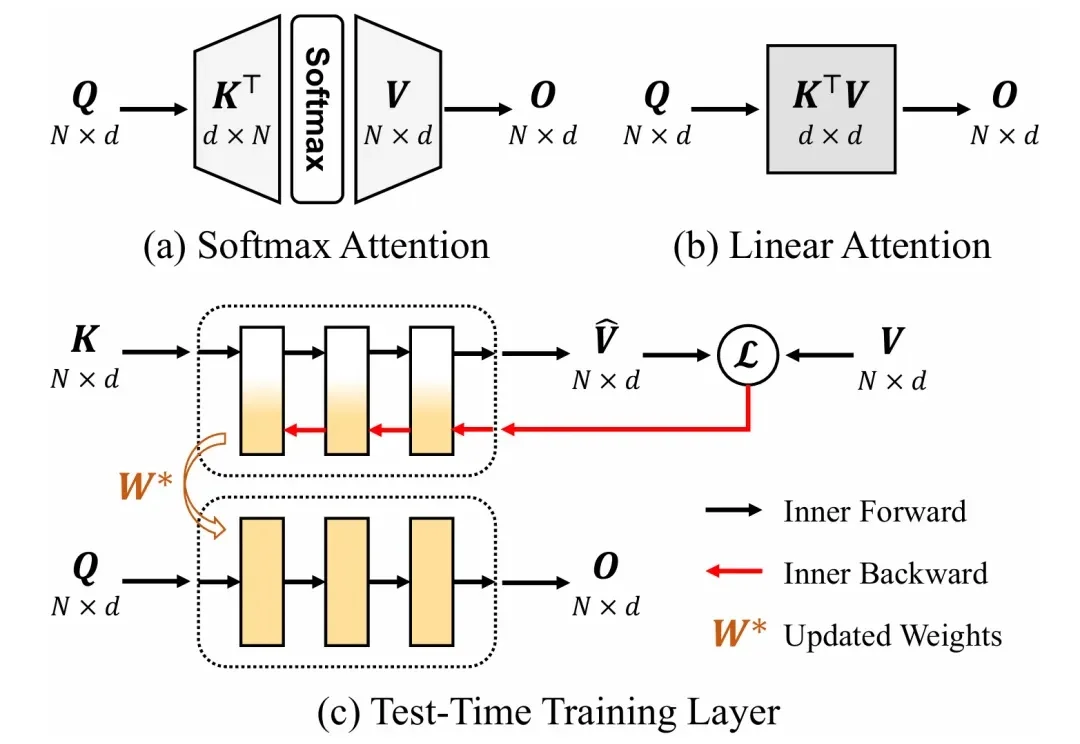
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。